Fui ao Google Cloud Next e Voltei Obcecada com Observabilidade de IA 🔗
O exemplo completo que menciono neste post está no repositório dash0-examples. Este post explica por que ele existe e o que você obtém ao rodá-lo.
Voltei do Google Cloud Next há uma semana e, honestamente, ainda estou processando tudo. Foi incrível. Foi minha primeira conferência do Google e superou todas as minhas expectativas. Além de ficar no estande fazendo demos em inglês e em português (sim!) eu percorri o expo hall e o único tema que apareceu em todo lugar, em cada sessão, cada estande, cada conversa de corredor, foi agentes. Agentes de IA.

Sistemas de IA tomando decisões, chamando ferramentas, iniciando outros agentes, escrevendo código, fazendo deploy de coisas. Fui esperando muito conteúdo sobre infraestrutura cloud e voltei com a cabeça cheia de pipelines agênticos.
E em algum momento do segundo dia, um pensamento surgiu que eu não conseguia tirar da cabeça:
Se isso começar a se comportar de forma estranha às 3 da manhã (respostas lentas, outputs errados, custos disparando), por onde você começa a procurar?
Essa pergunta me levou por uma toca de coelho porque você precisa conseguir ver o que há dentro. Não só “está de pé ou caiu.” Realmente ver o que está acontecendo dentro da IA.
Então eu construí uma demo pequena para entender como isso parece na prática. Comecei pela camada de inferência, especificamente o vLLM, que é o que muitas equipes usam para hospedar seus próprios modelos de IA (e é Open Source!). Vou compartilhar o que aprendi.
Primeiro: o que é vLLM e por que importa? 🔗
Se você já ouviu falar do ChatGPT mas não do vLLM, aqui está a versão rápida: ChatGPT é um produto. Por baixo tem um modelo (o cérebro real da IA) e um servidor que trata todas as requisições, como receber texto, passá-lo pelo modelo e retornar uma resposta.
O vLLM é um desses servidores. É o que muitas equipes usam quando querem hospedar seu próprio modelo de IA em vez de pagar pela API de outra pessoa. É rápido, é open source, e se tornou meio que o padrão para serving de IA self-hosted.

A parte interessante pra gente: o vLLM tem observabilidade embutida. Você pode configurá-lo para reportar automaticamente o que está fazendo, e esses dados fluem para suas ferramentas de monitoramento com quase nenhum código extra. Digo “quase” porque você precisa passar uma flag e configurar um collector, o que vou explicar mais adiante. Mas sem código de instrumentação personalizado na sua aplicação.
O que “observabilidade” significa para uma IA? 🔗
Eu entendo as coisas melhor usando analogias, então imagina que seu modelo de IA é uma cozinha de restaurante. Os clientes (usuários) fazem pedidos (requisições). A cozinha (o servidor de IA) prepara a comida (gera respostas) e devolve.
Agora algo dá errado. Os pedidos estão demorando demais. O que você faz?
Sem observabilidade, você está parado do lado de fora da cozinha sem janelas. Você sabe que os pedidos estão lentos. É só isso.
Com observabilidade, você consegue ver:
- Quantos pedidos estão esperando para começar
- Quais pedidos estão sendo preparados agora
- Qual etapa está demorando mais (é o preparo ou o cozimento?)
- O quão cheio está o espaço de trabalho da cozinha (se transbordar, os pedidos são interrompidos e precisam começar do zero)
Servidores web comuns têm versões de todos esses problemas. Mas servidores de IA têm seu próprio sabor de cada um, e os sinais que você precisa monitorar são completamente diferentes. É por isso que o vLLM traz sua própria camada de observabilidade.
Os dois tipos de dados que você obtém 🔗
Traces: rastreamento GPS da sua requisição 🔗
Um trace é um registro de tudo que aconteceu com uma única requisição. Cada etapa, em ordem, com timestamps.
Quando seu app manda uma pergunta para a IA:
- Seu app recebe a requisição
- Seu app busca algum contexto (se você usa RAG)
- Seu app chama o modelo de IA
- O servidor de IA agenda a requisição
- A IA gera a resposta, token por token
- A resposta volta
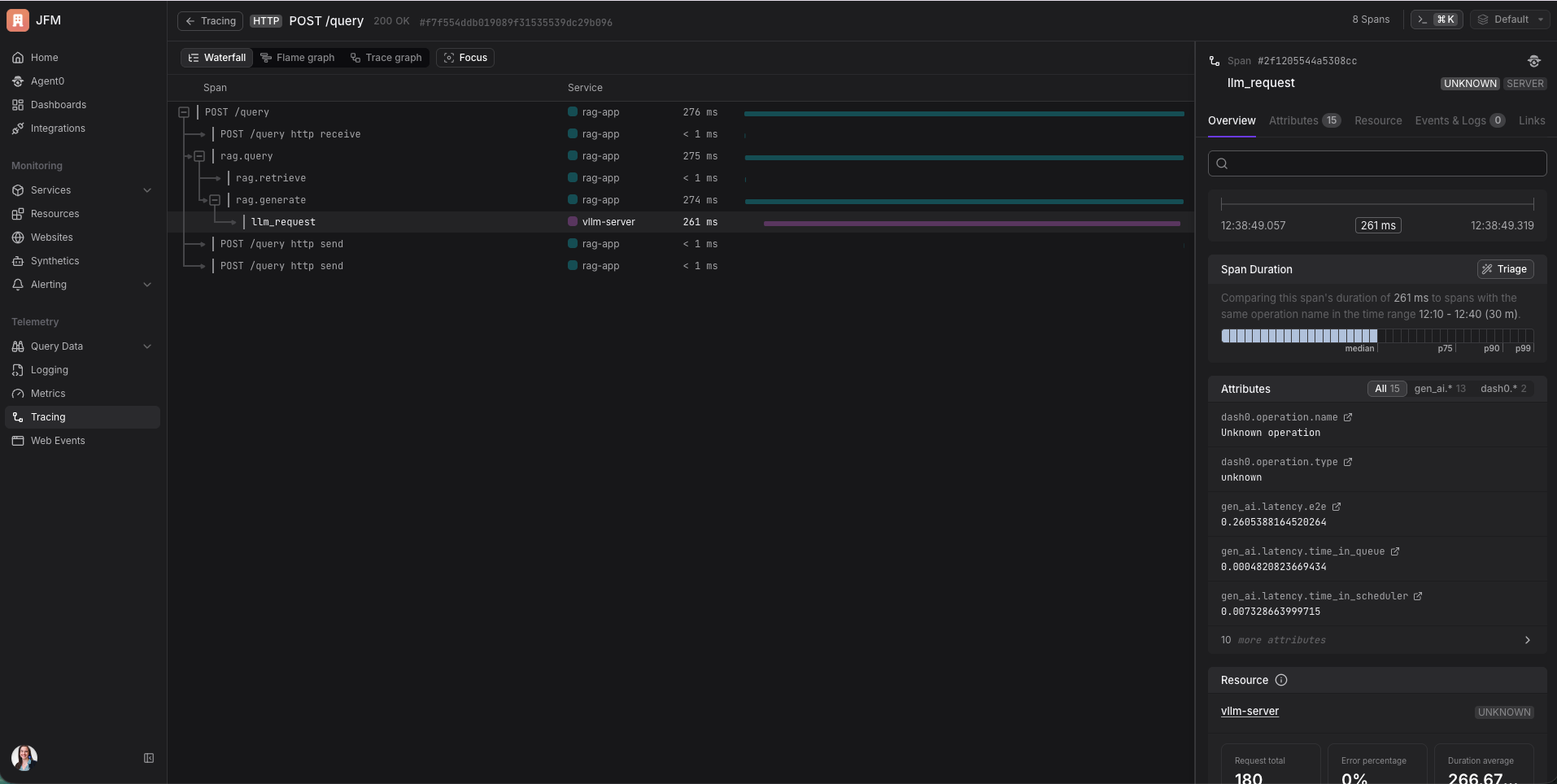
Um trace captura tudo isso e mostra exatamente onde o tempo foi. A IA estava lenta porque o servidor estava sobrecarregado com outras requisições? Estava lenta porque o prompt era muito longo? O trace te diz.
Se você configurar corretamente, você obtém um trace contínuo que atravessa múltiplos serviços. Meu app RAG e o servidor vLLM são dois processos separados, mas no Dash0 eu consigo vê-los como um waterfall conectado. “Meu app gastou 85ms buscando documentos e 360ms esperando a IA.” Em uma única view. Sem nenhuma plumbing extra além de injetar um header. É lindo de ver.
Métricas: o painel na parede da sua cozinha 🔗
Métricas são números que se atualizam ao longo do tempo. Menos detalhe que traces, mas mais fáceis de monitorar continuamente e de configurar alertas.
As que realmente importam:
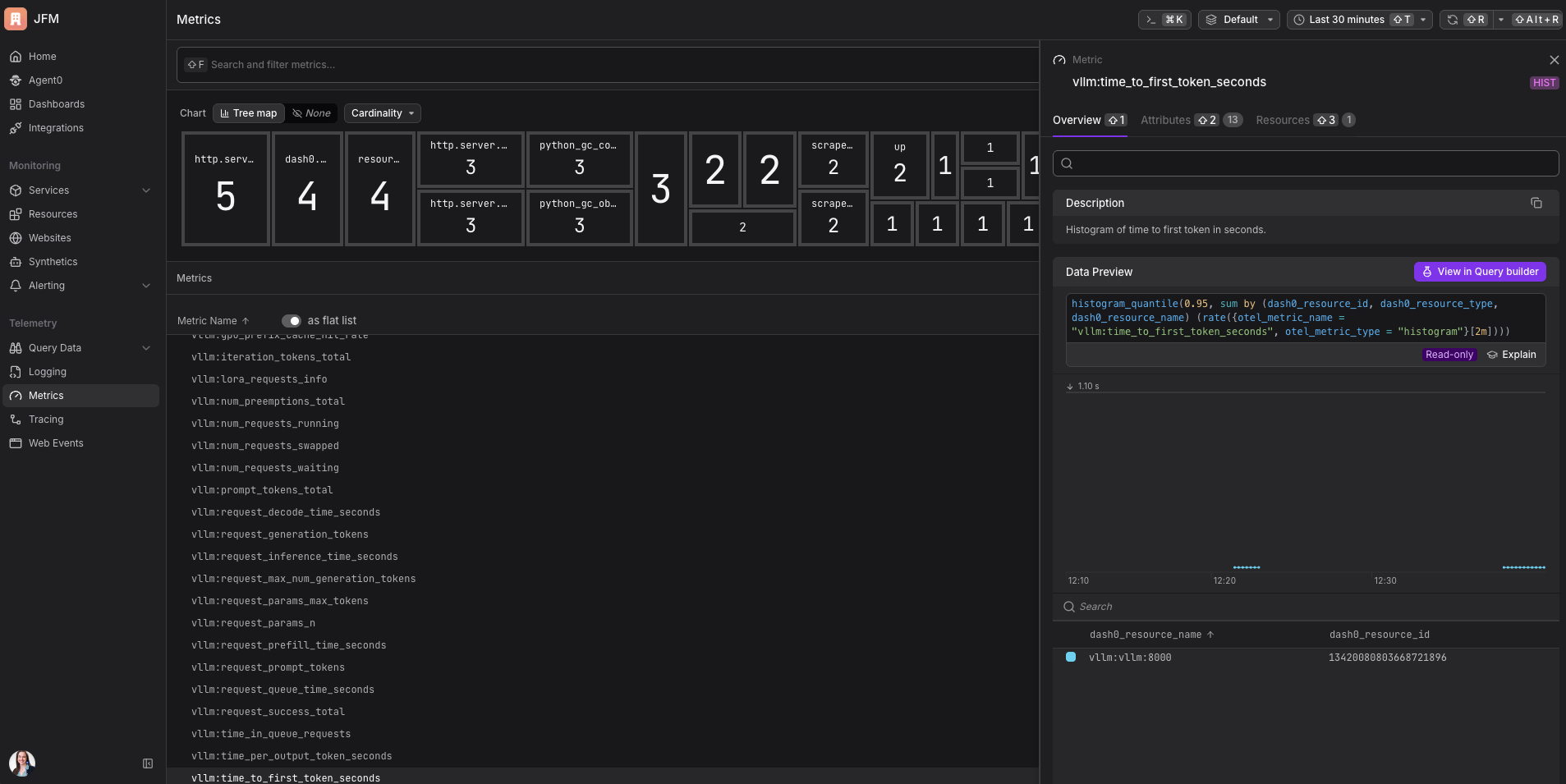
Tempo até o primeiro token. Quanto tempo até o usuário ver a primeira palavra da resposta. Para qualquer coisa com uma UI de streaming onde o texto aparece conforme é gerado, isso é o que determina se o produto se sente rápido. Eu não fazia ideia de que isso era medido separadamente da latência total antes de mergulhar no vLLM. Faz todo o sentido em retrospecto.
Uso do cache da GPU. Esse precisa de sua própria analogia. A GPU tem um tipo especial de memória de trabalho chamado KV cache. Pense nisso como o caderno de anotações de um chef: quando o chef está no meio de uma receita complexa, ele anota coisas para não perder o fio. A IA faz o mesmo durante a geração. Quando o caderno fica cheio, o chef precisa apagar as anotações de outra pessoa para abrir espaço, o que significa que o pedido dessa pessoa precisa começar do zero. No vLLM isso se chama preemption, e causa picos de latência repentinos que aparecem como requisições lentas em vez de erros. A métrica de uso do cache da GPU te diz o quão cheio está esse caderno antes de as coisas começarem a ser apagadas. Eu jamais teria pensado em monitorar essa métrica antes deste projeto. Agora é a primeira coisa que verifico.
Requisições esperando. Quantas requisições estão na fila mas ainda não estão sendo processadas. Isso sobe antes da latência explodir. É um indicador antecedente, exatamente o tipo de sinal que é útil para planejamento de capacidade.
Tokens por segundo. O throughput do seu setup. Útil para saber se você está aproveitando bem seu hardware.
Como os dados fluem 🔗
Aqui está a arquitetura em termos simples:
Seu app
│
│ manda uma pergunta
▼
vLLM (o servidor de IA)
│
├── envia dados de trace automaticamente → OTel Collector
└── expõe métricas em /metrics → OTel Collector faz scrape
│
│ encaminha tudo
▼
Dash0
(onde você vê tudo)
O OTel Collector é um intermediário que recebe dados de múltiplas fontes e os encaminha para seu backend de observabilidade. Pense nisso como a sala de correspondência de um prédio: tudo passa por lá antes de chegar ao destino final. Ele também cuida de coisas como batching, retentativas e enriquecimento da telemetria com contexto extra, por isso você quer tê-lo no pipeline em vez de enviar diretamente.
OpenTelemetry (OTel) é o formato padrão que tudo isso usa. É vendor-neutral, o que significa que o mesmo setup funciona tanto faz se você está enviando para Dash0, Grafana, ou qualquer outra ferramenta que fala OTel. Eu uso Dash0 porque é onde trabalho, rs. Ver as métricas e traces do vLLM aparecendo na mesma view sem escrever nenhum código de cola foi o momento em que tudo realmente fez sentido pra mim. Se você quer entender por que ser OTel-native importa, esse post explica bem.
Como configurar 🔗
O setup completo está no repositório dash0-examples.
O que você precisa:
- Docker e Docker Compose
- Uma máquina com GPU NVIDIA
- Uma conta Dash0 (baseada em consumo, grátis por 14 dias)
A questão da GPU. Isso me pegou de surpresa. Achei que podia só rodar a demo na minha Mac, talvez lentamente. Não mesmo. A imagem Docker do vLLM é compilada especificamente para NVIDIA CUDA. Não é uma situação de “roda mais devagar sem GPU”, simplesmente não roda. Passei uma quantidade constrangedora de tempo tentando fazer funcionar antes de aceitar a realidade e subir uma instância no Google Cloud.
Para os testes usei uma n1-standard-4 com uma GPU T4 no Google Cloud (cerca de $0.50/hora). Mais que suficiente para o modelo pequeno desta demo. Uma coisa importante a verificar antes de tentar: o Google Cloud limita por padrão quantas GPUs você pode usar, às vezes a zero. Vá em IAM & Admin → Cotas no Console do Google Cloud, procure por NVIDIA_T4_GPUS, selecione sua região e solicite um aumento. Geralmente é aprovado em poucas horas. Eu não sabia que isso existia até bater no limite e receber um erro críptico em vez de uma mensagem útil.
A parte boa do Google Cloud: você pode fazer SSH na sua instância com gcloud compute ssh em vez de gerenciar arquivos .pem. Sem chmod 400, sem “onde coloquei aquela chave?":
gcloud compute ssh nome-da-sua-instancia --zone=us-central1-a
E quando terminar de usar, lembre de parar a instância!! Caso contrário você vai receber uma fatura enorme no fim do mês.
A espera ao carregar o modelo. Na primeira vez que você roda docker compose up, o vLLM baixa os pesos do modelo e os carrega na memória da GPU. Isso leva de 2 a 5 minutos. O stack parece congelado. Não está congelado. Espere por esta linha antes de enviar qualquer requisição:
INFO: Application startup complete.
Na minha primeira tentativa mandei requisições antes de ver essa linha. Fiquei muito confusa sobre por que nada funcionava. Agora você já sabe.
Passos:
-
Clone o repositório:
git clone https://github.com/dash0hq/dash0-examples.git cd dash0-examples/vllm -
Adicione suas credenciais do Dash0 ao arquivo
.envna raiz do repositório. Você encontra as credenciais na página de configurações da sua conta.DASH0_AUTH_TOKEN=seu_token_aqui DASH0_DATASET=default DASH0_ENDPOINT_OTLP_GRPC_HOSTNAME=ingress.us-west-2.aws.dash0.com DASH0_ENDPOINT_OTLP_GRPC_PORT=4317 -
Inicie tudo (requer GPU NVIDIA, ou veja a seção de configuração do vLLM no mergulho técnico detalhado para saber como rodar em CPU):
docker compose up --build -
Espere o modelo carregar. Procure
Application startup complete.nos logs. -
Mande uma requisição de teste:
python scripts/send-request.py
Depois vá ao Dash0. Os dados devem estar fluindo.
O que você realmente vê 🔗
Essa é a parte que fez tudo valer a pena.
Nos traces, cada requisição aparece como uma árvore conectada. Você consegue ver o fluxo completo desde o seu app recebendo a requisição até a IA terminando de gerar, com o tempo em cada etapa. O span da IA tem atributos mostrando quantos tokens estavam no prompt, quantos foram gerados, e como a latência se distribui dentro do vLLM (tempo esperando na fila, tempo em prefill, tempo em decode).
Nas métricas, você tem uma view em tempo real da saúde do servidor de IA. O cache da GPU está enchendo? Está se formando uma fila? A métrica em que eu colocaria um alerta primeiro: tempo até o primeiro token no percentil 95. Se isso estiver subindo, os usuários estão sentindo antes de qualquer outra coisa quebrar.
Por que isso importa além da demo 🔗
É nisso que eu não parei de pensar no voo de volta do Google Cloud Next.
Os agentes que todo mundo estava demonstrando não são modelos únicos. São pipelines com um orquestrador chamando ferramentas, buscando dados, iniciando sub-agentes, chamando um modelo, processando o resultado, chamando o modelo novamente. Cada etapa pode falhar. Cada etapa tem latência. Sem instrumentação você está depurando esse sistema completamente no escuro.
Mas se cada componente propagar o contexto de trace através de suas chamadas, e se a camada de IA emitir seus próprios spans, você acaba com um trace contínuo por interação de usuário que cobre toda a execução. Você consegue ver onde o tempo foi, quais chamadas de ferramenta foram lentas, e se o gargalo foi o modelo ou a infraestrutura ao redor.
É isso que eu queria conseguir fazer. Esta demo é o primeiro passo. Muita gente na comunidade cloud-native está trabalhando nesse mesmo problema agora. Ainda não tenho todas as respostas, mas acho que construir e compartilhar ao longo do caminho é como vamos resolver isso juntos.
Se você quiser ver como a observabilidade agêntica parece uma vez que a infraestrutura está no lugar, o Dash0 tem um guia prático que vale a pena ler junto com este post.
Experimente você mesmo 🔗
O exemplo completo está em dash0-examples/vllm. Clone, aponte para o seu modelo, e veja sua camada de inferência se tornar observável em minutos. Comece seu trial gratuito do Dash0 se ainda não tiver uma conta.
Se você tentar e ficar com dúvidas em alguma coisa, me encontra no LinkedIn. E se você já está pensando em como estender isso para pipelines de agentes completos, eu também estou. É nisso que estou trabalhando a seguir. 💙